Crivo de Eratóstenes¶
O Crivo de Eratóstenes é um algoritmo para encontrar todos os números primos em um segmento $[1;n]$ usando $O(n \log \log n)$ operações.
O algoritmo é muito simples: no começo, escrevemos todos os números entre 2 e $n$. Marcamos todos os múltiplos próprios de 2 (já que 2 é o menor número primo) como compostos. Um múltiplo próprio de um número $x$ é um número maior que $x$ e divisível por $x$. Então, encontramos o próximo número que não foi marcado como composto, neste caso, é o 3. O que significa que 3 é primo, e marcamos todos os múltiplos próprios de 3 como compostos. O próximo número não marcado é o 5, que é o próximo número primo, e marcamos todos os seus múltiplos próprios. E continuamos esse procedimento até processarmos todos os números na linha.
Na imagem a seguir, você pode ver uma visualização do algoritmo para calcular todos os números primos no intervalo $[1; 16]$. Pode-se observar que, com bastante frequência, marcamos números como compostos várias vezes.
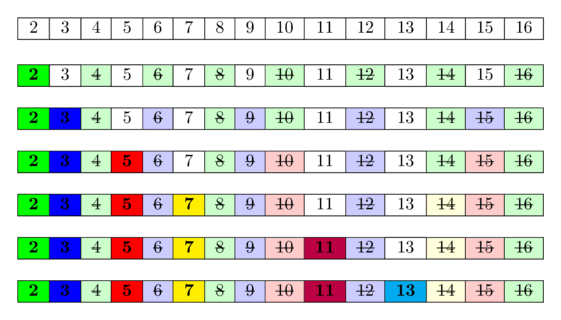
A ideia por trás disso é: Um número é primo se nenhum dos números primos menores o divide. Como iteramos sobre os números primos em ordem, já marcamos todos os números que são divisíveis por pelo menos um dos números primos como divisíveis. Portanto, se alcançarmos uma célula e ela não estiver marcada, então o número correspondente não é divisível por nenhum número primo menor e, portanto, deve ser primo.
Implementação¶
int n;
vector<bool> is_prime(n+1, true);
is_prime[0] = is_prime[1] = false;
for (int i = 2; i <= n; i++) {
if (is_prime[i] && (long long)i * i <= n) {
for (int j = i * i; j <= n; j += i)
is_prime[j] = false;
}
}
Este código primeiro marca todos os números exceto zero e um como potenciais números primos, depois começa o processo de peneirar os números compostos.
Para isso, ele itera sobre todos os números de $2$ a $n$.
Se o número atual $i$ for um número primo, ele marca todos os números que são múltiplos de $i$ como números compostos, começando a partir de $i^2$.
Isso já é uma otimização sobre a maneira ingênua de implementá-lo, e é permitido, pois todos os números menores que são múltiplos de $i$ necessariamente também têm um fator primo que é menor que $i$, então todos eles já foram peneirados anteriormente.
Como $i^2$ pode facilmente causar overflow no tipo int, a verificação adicional é feita usando o tipo long long antes do segundo loop aninhado.
Usando essa implementação, o algoritmo consome $O(n)$ de memória (obviamente) e realiza $O(n \log \log n)$ operações (veja a próxima seção).
Análise assintótica¶
É simples provar um tempo de execução de $O(n \log n)$ sem saber nada sobre a distribuição de números primos - ignorando a verificação is_prime, o loop interno é executado (no máximo) $n/i$ vezes para $i = 2, 3, 4, \dots$, levando o número total de operações no loop interno a ser uma soma harmônica como $n(1/2 + 1/3 + 1/4 + \cdots)$, que é limitada por $O(n \log n)$.
Vamos provar que o tempo de execução do algoritmo é $O(n \log \log n)$. O algoritmo executará $\frac{n}{p}$ operações para cada primo $p \le n$ no loop interno. Portanto, precisamos avaliar a seguinte expressão:
Vamos relembrar dois fatos conhecidos.
- O número de números primos menores ou iguais a $n$ é aproximadamente $\frac n {\ln n}$.
- O $k$-ésimo número primo é aproximadamente igual a $k \ln k$ (isso segue do fato anterior).
Assim, podemos escrever a soma da seguinte maneira:
Aqui, extraímos o primeiro número primo 2 da soma, porque $k = 1$ na aproximação $k \ln k$ é $0$ e causa uma divisão por zero.
Agora, vamos avaliar essa soma usando a integral de uma mesma função sobre $k$ de $2$ a $\frac n {\ln n}$ (podemos fazer tal aproximação porque, de fato, a soma está relacionada à integral como sua aproximação usando o método do retângulo):
A antiderivada para o integrando é $\ln \ln k$. Usando uma substituição e removendo termos de ordem inferior, obteremos o resultado:
Agora, retornando à soma original, obteremos sua avaliação aproximada:
Você pode encontrar uma prova mais rigorosa (que dá uma avaliação mais precisa dentro de multiplicadores constantes) no livro de Hardy & Wright "An Introduction to the Theory of Numbers" (p. 349).
Diferentes otimizações do Crivo de Eratóstenes¶
A maior fraqueza do algoritmo é que ele "caminha" pela memória várias vezes, manipulando apenas elementos únicos. Isso não é muito amigável ao cache. E por causa disso, a constante que está oculta em $O(n \log \log n)$ é comparativamente grande.
Além disso, a memória consumida é um gargalo para um $n$ grande.
Os métodos apresentados abaixo nos permitem reduzir a quantidade de operações executadas, bem como diminuir notavelmente a memória consumida.
Peneirando até a raiz¶
Obviamente, para encontrar todos os números primos até $n$, bastará realizar o peneiramento apenas pelos números primos que não excedam a raiz de $n$.
int n;
vector<bool> is_prime(n+1, true);
is_prime[0] = is_prime[1] = false;
for (int i = 2; i * i <= n; i++) {
if (is_prime[i]) {
for (int j = i * i; j <= n; j += i)
is_prime[j] = false;
}
}
Tal otimização não afeta a complexidade (de fato, ao repetir a prova apresentada acima, obteremos a avaliação $n \ln \ln \sqrt n + o(n)$, que é assintoticamente a mesma de acordo com as propriedades dos logaritmos), embora o número de operações seja reduzido notavelmente.
Peneirando apenas pelos números ímpares¶
Como todos os números pares (exceto $2$) são compostos, podemos parar de verificar os números pares completamente. Em vez disso, precisamos operar apenas com números ímpares.
Primeiro, isso nos permitirá reduzir a memória necessária pela metade. Segundo, reduzirá o número de operações executadas pelo algoritmo aproximadamente pela metade.
Consumo de memória e velocidade das operações¶
Devemos notar que essas duas implementações do Crivo de Eratóstenes usam $n$ bits de memória usando a estrutura de dados vector<bool>.
vector<bool> não é um contêiner regular que armazena uma série de bool (como na maioria das arquiteturas de computadores, um bool ocupa um byte de memória).
É uma especialização de otimização de memória do vector<T>, que consome apenas $\frac{N}{8}$ bytes de memória.
As arquiteturas de processadores modernos funcionam de forma muito mais eficiente com bytes do que com bits, pois geralmente não podem acessar os bits diretamente.
Portanto, por baixo, o vector<bool> armazena os bits em uma memória contínua grande, acessa a memória em blocos de alguns bytes e extrai/define os bits com operações bit a bit, como mascaramento e deslocamento de bits (bit masking e bit shifting).
Por causa disso, há uma certa sobrecarga quando você lê ou escreve bits com um vector<bool>, e com bastante frequência, usar um vector<char> (que usa 1 byte para cada entrada, portanto, 8x a quantidade de memória) é mais rápido.
No entanto, para as implementações simples do Crivo de Eratóstenes, usar um vector<bool> é mais rápido.
Você é limitado pela velocidade com que pode carregar os dados no cache e, portanto, usar menos memória oferece uma grande vantagem.
Um benchmark (link) mostra que usar um vector<bool> é entre 1,4x e 1,7x mais rápido do que usar um vector<char>.
As mesmas considerações também se aplicam ao bitset.
É também uma maneira eficiente de armazenar bits, semelhante ao vector<bool>, por isso leva apenas $\frac{N}{8}$ bytes de memória, mas é um pouco mais lento no acesso aos elementos.
No benchmark acima, o bitset tem um desempenho um pouco pior que o vector<bool>.
Outra desvantagem do bitset é que você precisa saber o tamanho no tempo de compilação.
Crivo Segmentado¶
Segue-se da otimização "peneirando até a raiz" que não há necessidade de manter todo o array is_prime[1...n] em todos os momentos.
Para o peneiramento, basta manter os números primos até a raiz de $n$, ou seja, prime[1... sqrt(n)], dividir o intervalo completo em blocos e peneirar cada bloco separadamente.
Seja $s$ uma constante que determina o tamanho do bloco, então temos $\lceil {\frac n s} \rceil$ blocos no total, e o bloco $k$ ($k = 0 ... \lfloor {\frac n s} \rfloor$) contém os números em um segmento $[ks; ks + s - 1]$. Podemos trabalhar nos blocos por vez, ou seja, para cada bloco $k$ vamos passar por todos os números primos (de $1$ a $\sqrt n$) e realizar o peneiramento usando-os. Vale ressaltar que temos que modificar um pouco a estratégia ao lidar com os primeiros números: primeiro, todos os números primos de $[1; \sqrt n]$ não devem remover a si mesmos; e segundo, os números $0$ e $1$ devem ser marcados como números não primos. Enquanto trabalhamos no último bloco, não se deve esquecer que o último número necessário $n$ não está necessariamente localizado no final do bloco.
Como discutido anteriormente, a implementação típica do Crivo de Eratóstenes é limitada pela rapidez com que você pode carregar dados nos caches da CPU.
Ao dividir o intervalo de números primos potenciais $[1; n]$ em blocos menores, nunca precisamos manter vários blocos na memória ao mesmo tempo, e todas as operações são muito mais amigáveis ao cache.
Como agora não estamos mais limitados pelas velocidades do cache, podemos substituir o vector<bool> por um vector<char> e ganhar algum desempenho adicional, pois os processadores podem lidar com leitura e escrita com bytes diretamente e não precisam depender de operações bit a bit para extrair bits individuais.
O benchmark (link) mostra que usar um vector<char> é cerca de 3x mais rápido nesta situação do que usar um vector<bool>.
Um aviso: esses números podem diferir dependendo da arquitetura, compilador e níveis de otimização.
Aqui temos uma implementação que conta o número de primos menores ou iguais a $n$ usando o peneiramento de blocos.
int count_primes(int n) {
const int S = 10000;
vector<int> primes;
int nsqrt = sqrt(n);
vector<char> is_prime(nsqrt + 2, true);
for (int i = 2; i <= nsqrt; i++) {
if (is_prime[i]) {
primes.push_back(i);
for (int j = i * i; j <= nsqrt; j += i)
is_prime[j] = false;
}
}
int result = 0;
vector<char> block(S);
for (int k = 0; k * S <= n; k++) {
fill(block.begin(), block.end(), true);
int start = k * S;
for (int p : primes) {
int start_idx = (start + p - 1) / p;
int j = max(start_idx, p) * p - start;
for (; j < S; j += p)
block[j] = false;
}
if (k == 0)
block[0] = block[1] = false;
for (int i = 0; i < S && start + i <= n; i++) {
if (block[i])
result++;
}
}
return result;
}
O tempo de execução do peneiramento de blocos é o mesmo que o do Crivo de Eratóstenes regular (a menos que o tamanho dos blocos seja muito pequeno), mas a memória necessária diminuirá para $O(\sqrt{n} + S)$ e teremos melhores resultados de cache. Por outro lado, haverá uma divisão para cada par de um bloco e número primo de $[1; \sqrt{n}]$, e isso será muito pior para tamanhos de bloco menores. Portanto, é necessário manter o equilíbrio ao selecionar a constante $S$. Alcançamos os melhores resultados para tamanhos de bloco entre $10^4$ e $10^5$.
Encontrar primos em um intervalo¶
Às vezes, precisamos encontrar todos os números primos em um intervalo $[L,R]$ de tamanho pequeno (por exemplo, $R - L + 1 \approx 1e7$), onde $R$ pode ser muito grande (por exemplo, $1e12$).
Para resolver tal problema, podemos usar a ideia do Crivo Segmentado. Nós pré-geramos todos os números primos até $\sqrt R$ e usamos esses primos para marcar todos os números compostos no segmento $[L, R]$.
vector<char> segmentedSieve(long long L, long long R) {
// gerar todos os primos até sqrt(R)
long long lim = sqrt(R);
vector<char> mark(lim + 1, false);
vector<long long> primes;
for (long long i = 2; i <= lim; ++i) {
if (!mark[i]) {
primes.emplace_back(i);
for (long long j = i * i; j <= lim; j += i)
mark[j] = true;
}
}
vector<char> isPrime(R - L + 1, true);
for (long long i : primes)
for (long long j = max(i * i, (L + i - 1) / i * i); j <= R; j += i)
isPrime[j - L] = false;
if (L == 1)
isPrime[0] = false;
return isPrime;
}
Também é possível não pré-gerar todos os números primos:
vector<char> segmentedSieveNoPreGen(long long L, long long R) {
vector<char> isPrime(R - L + 1, true);
long long lim = sqrt(R);
for (long long i = 2; i <= lim; ++i)
for (long long j = max(i * i, (L + i - 1) / i * i); j <= R; j += i)
isPrime[j - L] = false;
if (L == 1)
isPrime[0] = false;
return isPrime;
}
Obviamente, a complexidade é pior, que é $O((R - L + 1) \log (R) + \sqrt R)$. No entanto, ainda funciona muito rápido na prática.
Modificação de tempo linear¶
Podemos modificar o algoritmo de forma que ele tenha apenas complexidade de tempo linear. Essa abordagem é descrita no artigo Crivo Linear. No entanto, este algoritmo também tem as suas próprias fraquezas.
Problemas Práticos¶
- Leetcode - Four Divisors
- Leetcode - Count Primes
- SPOJ - Printing Some Primes
- SPOJ - A Conjecture of Paul Erdos
- SPOJ - Primal Fear
- SPOJ - Primes Triangle (I)
- Codeforces - Almost Prime
- Codeforces - Sherlock And His Girlfriend
- SPOJ - Namit in Trouble
- SPOJ - Bazinga!
- Project Euler - Prime pair connection
- SPOJ - N-Factorful
- SPOJ - Binary Sequence of Prime Numbers
- UVA 11353 - A Different Kind of Sorting
- SPOJ - Prime Generator
- SPOJ - Printing some primes (hard)
- Codeforces - Nodbach Problem
- Codeforces - Colliders